Человек воспринимает текстовую информацию непосредственно в виде символов, визуально. Компьютер — машина в первую очередь числовая и наиболее быстро может работать только с числами. Поэтому для того, чтобы тексты можно было наиболее эффективно обрабатывать (получать, передавать, хранить, воспроизводить, производить поиск, сортировать и т.п.) на компьютере, символы алфавита нужно преобразовать в числа, т.е. сопоставить каждому символу число (код). Таблица, которая задает соответвия между символами и их кодами, называется кодировкой.
Очевидно, что даже для одного алфавита можно составить очень большое количество таких таблиц. Большое число таблиц может вносить путаницу при обработке тестовой информации.
Больше всего повезло латинице — т.к. разработчики компьтерной техники в основном находятся в странах, использующих латиницу, то латинская кодировка была принята очень давно в единственном варианте и никогда не изменялась. Она известна под названием ASCII (Американский Стандартный Код Обмена Информацией). В нем для кодирования одного символа используется 1 байт. Таким образов в ASCII можно закодировать 256 символов, что более чем достаточно для латиницы. Оставшиеся место используется для символов греческого и германского алфавита, а также псевдо-графики — символов, из которых можно строить таблицы и некоторые простейшие рисунки.
Хуже оказалось с другими алфавитами. Например для кириллицы известно как минимум 7 кодировок (КОИ8, CP-866, IBM-855, ISO-8859-5, ISO-IR-111, Windows-1251, MacCyrillic). Каждый производитель оборудования или ПО придумывал что-то свое. Тем не менее все эти кодировки основывались на ASCII — 1 байт для одного символа, латиница остается на своем месте, кириллица распологается на оставшийся части.
Понятно, что такое большое число кодировок вносят существенную путаницу при обработке тестовой информации. Текст в неправильной кодировке может быть нечитаемым, а также неправильно обрабатываться. Для того, чтобы положить конец путанице, была разработана кодировка UNICODE. В UNICODE каждый символ кодируется 4-мя байтами, что позволяет закодировать символы алфавитов всех стран мира и использовать только одну кодировку.
Для совместимости с ASCII существует вариант UNICODE c кодированием переменным числом байт на символ: UTF-8. Для кодирования одного символа используется от 1 до 6 байт. Такой способ позволяет сохранить совместимость с ACSII в части латиницы и служебных символов, также автоматически для латиницы остается тот же размер текста, т.к. латинские символы по-прежнему кодируются одном байтом. Символы других алфавитов кодируются большим числом байт. Количество байт в символе кодируется количеством старших единиц в первом байте:
0XXXXXXX - один байт, символ латинского алфавита; 110XXXXX - два байта; 1110XXXX - три байта; 11110XXX - четыре байта; 111110XX - пять байт; 10XXXXXX - второй и последующие байты;
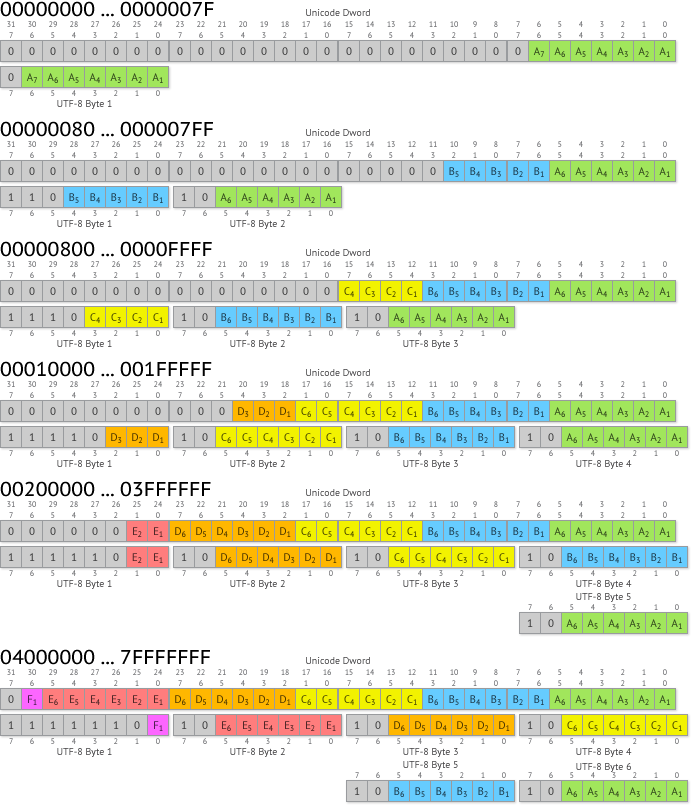
Таким образом, для кодирования символов не латинских алфавитов используется переменное количество бит: 7, 11, 16, 19, 24, 31. Это позволяет использовать в одном тексте до 2 млрд. символов (2^31) не сильно увеличивая объем текста, разместив наиболее часто используемые кодировки на кодах с малым числом байт.